Java中的集合
先来看看Java的集合类导图。
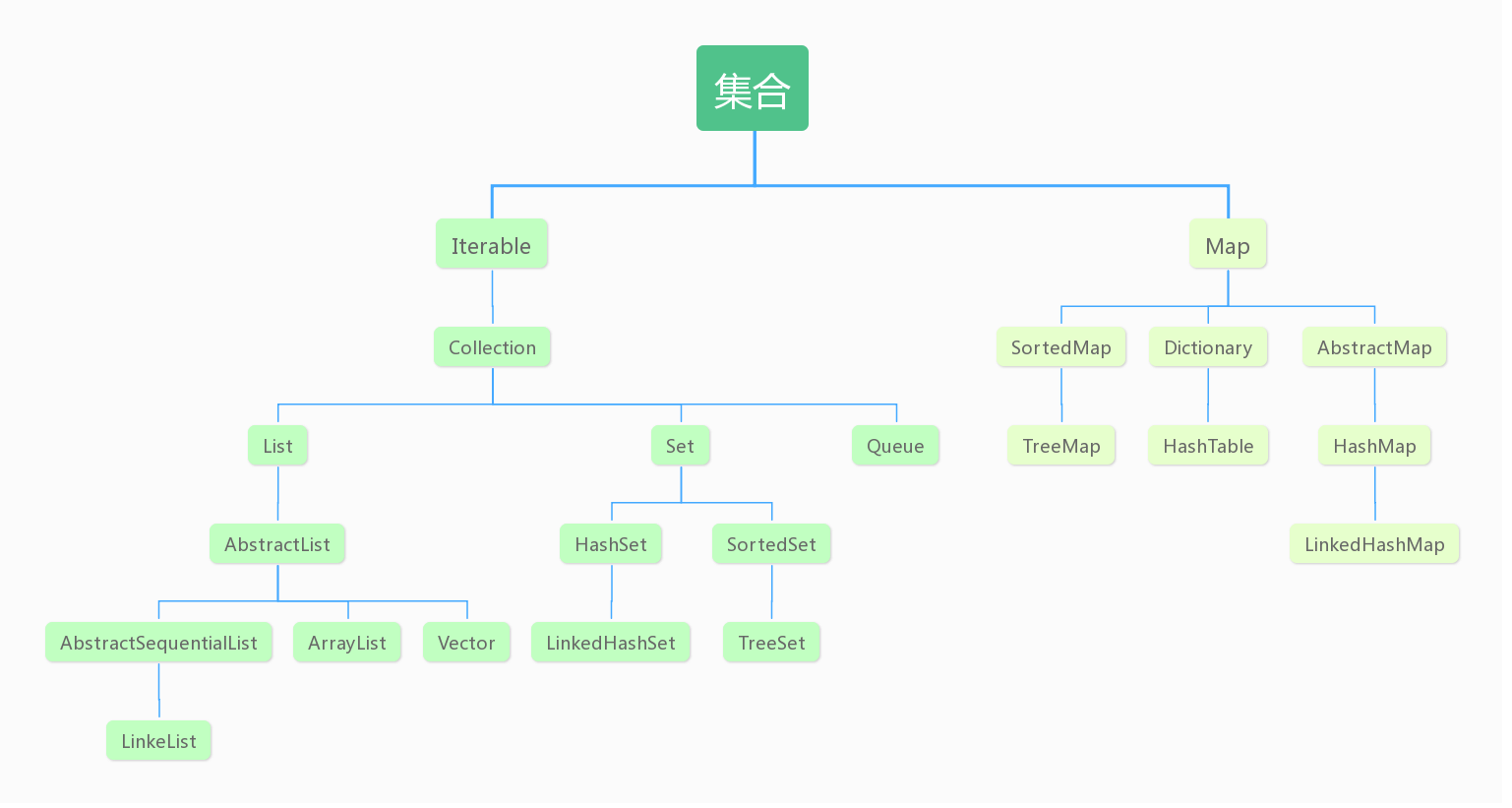
首先来看Collection的末节点的类
LinkedList
LinkedList 是维护一组节点的列表,节点包括节点本身、下一个节点及上一个节点。
在JDK1.6时,LinkedList只有一个头结点(header),列表中的第一个元素的上一个节点永远指向header节点,而列表中的最后一个节点的下一个节点也永远指向header,这就构成了一个以header为开头和结尾的循环链表。
在JDK1.7之后,LinkedList维护一个头结点(first)和一个尾节点(last),列表中的第一个元素的上一个节点永远为null,而最后一个节点的下一个节点永远为null,构成了一个非循环链表。
1.7对比1.6的优化:
- first / last有更清晰的链头、链尾概念,代码看起来更容易明白。
- first / last方式能节省new一个headerEntry。
实例化headerEntry是为了让后面的方法更加统一,否则会多很多header的空校验
- 在链头/尾进行插入/删除操作,first /last方式更加快捷。
插入/删除操作按照位置,分为两种情况:中间 和 两头。
在中间插入/删除,两者都是一样,先遍历找到index,然后修改链表index处两头的指针。
在两头,对于循环链表来说,由于首尾相连,还是需要处理两头的指针。而非循环链表只需要处理一边first.previous/last.next,所以理论上非循环链表更高效。恰恰在两头(链头/链尾) 操作是最普遍的
LinkedList在进行插入/移除操作时,只需要改变指针的指向(把链表断开,插入/删除元素,再把链表连起来)即可,使Linked的写入操作性能非常高。
但是LinkedList在随机访问的时候效率就会很低,因为它需要遍历节点才可以找到元素。
适用场景:
- 写入/移除操作频繁
- 随机访问少
- 不需要考虑线程安全
ArrayList
ArrayList 底层基于数组实现,在初始化时需要指定初始容量,默认容量为10,当数组容量已满时,需要进行扩容,ArrayList扩容时,按照当前容量的1.5倍生成一个新的数组,后将原数组拷贝到新数组中,最后将数组对象指针指向新数组。
ArrayList是一个动态数组,实现了RandomAccess接口,支持随机访问,通过get(i)即可获得相应内存中存放的值。原因是因为ArrayList存放的内容在内存中是连续的,数组直接用[ ]访问,相当于直接操作内存地址,所以随机访问的效率较高。
但是ArrayList内部空间总是有限的,每当内部容量被占满,就需要进行扩容,因此在插入/移除操作时,会带来性能上的损耗。
使用场景:
- 写入/移除操作少
- 读多
- 不需要考虑线程安全
Vector
Vector 是ArrayList线程安全版本,Vector在所有方法上都加了synchronized关键字,同一时刻,只有一个线程可以进入同一个Vector对象,保证了线程的安全性,但是降低了性能。
一般不使用Vector。
先转过头看完Map再来理解Set
HashMap
以下内容根据Java8编辑。
Map 是维护一组键值对关系的集合。
HashMap 中使用数组+链表+红黑树的数据结构。
HashMap在插入数据时的步骤:
- 通过获取key.hashCode()
- 做一次扰动运算 (h = key.hashCode()) ^ (h >>> 16)),目的是为了减少Hash碰撞
- 检查数组是否已经初始化
- 如果数据未初始化则先初始化数组
- 初始化数组之后,使用扰动后的hash值与当前HashMap的数组容量减一的值做一次与运算(hash& table.length-1),计算插入的键值对在数组中的索引位置。
- 判断当前索引位置是否为空
- 如果当前位置为空,则将此键值对直接放入数组
- 如果当前位置不为空,则继续比对此位置的旧数据中key与新key是否相等
- 如果相等,则替换,并返回旧值
- 如果不相等,则先判断此处节点是红黑树节点还是链表节点
- 如果是红黑树节点,则插入红黑树
- 如果是链表,遍历链表将新节点插入尾端
- 计算链表长度,如果链表长度大于8则转换为红黑树节点
- 判断数组长度是否达到 容量*加载因子 的值
- 如果是则扩容
- 如果不是则返回结果
扩容机制:
当HashMap中的键值对数量达到 阈值=容量*加载因子 时,开始扩容。
- 扩容时 ,先生成一个当前容量的两倍大小的数组。
- 遍历原数组、链表及红黑树中的节点,迁移到新数组。
- 如果原节点e的(e.hash & oldTable.length == 0),则e在新数组的索引位置同旧数组的索引位置相同。
- 如果如果原节点e的(e.hash & oldTable.length != 1),则e在新数组的索引位置等于旧数组的索引位置+旧数组的长度。
- 根据链表长度是否超过8判断是否将链表转换为红黑树。
- 将数组的引用指向新数组。
- 修改 阈值=新容量*加载因子
- 扩容完成
在jdk1.7中,在扩容的迁移节点步骤在多线程环境下会产生死循环。
而在jdk1.8中,多线程引起的死循环则产生在链表到红黑树相互转换时。
除了死循环的问题,在多线程环境下,HashMap可能会丢失数据。
其他1.7与1.8中的不同之处,到时候另开篇来讲。
HashTable
HashTable 也是维护一组键值对关系的集合。
与HashMap不一样的是:
- 是线程安全的,很多方法有synchronized修饰,单线程环境下因为加锁导致效率低。
- key/value都不允许为空,而HashMap允许一组key为空,多个value为空。
- Hashtable的hash算法散射不均匀,容易产生hash冲突。
- Hashtable的扩容将先创建一个长度为原长度2倍的数组,再使用头插法将链表进行反序。
- HashTable的数据结构为数组+链表。
LinkedHashMap
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。
在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。
可根据 插入顺序排序,也可以根据访问顺序排序。
更详细的内容可以参照博文[https://segmentfault.com/a/1190000012964859](LinkedHashMap 源码详细分析(JDK1.8)) 作者:coolblog
TreeMap
TreeMap 继承自SortedMap,是有序的键值对集合。
TreeMap 的数据结构是红黑树,根据自然排序。
在使用TreeMap时,有两点要求:
- 要么对象需实现Comparable接口。
- 要么在构造TreeMap时传入Comparator实现。
先回过头来理解Set
HashSet
Set是维护一组数据不重复的集合。
HashSet 是基于 HashMap 实现的,底层采用 HashMap 来保存元素,HashMap中的Key值即为HashSet中的值,而HashMap中的value则为空对象(private static final Object PRESENT = new Object();)。
LinkedHashSet
原理同HashSet,基于LinkedHashSet实现。
TreeSet
原理同HashSet,基于TreeMap实现。